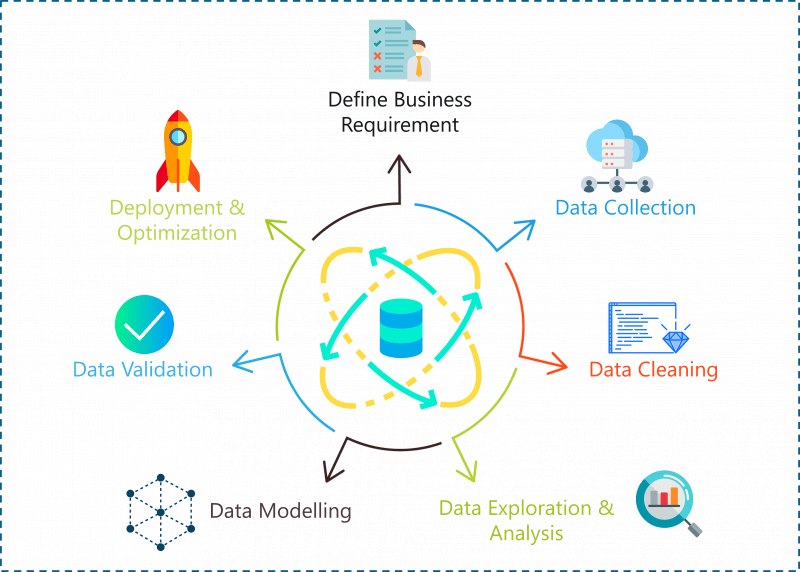
Complete life cycle of data science project
With the exponential outburst of AI, companies are eagerly looking to hire skilled Data Scientists to grow their business. Apart from getting a Data Science Certification, it is always good to have a couple of Data Science Projects on your resume. Having theoretical knowledge is never enough
Topics covered in this article:
- steps in the life cycle of data science project
- some websites where you can get projects and data set
Data science project life cycle
-->Given the right data, Data Science can be used to solve problems ranging from fraud detection and smart farming to predicting climate change and heart diseases. With that being said, data isn’t enough to solve a problem, you need an approach or a method that will give you the most accurate results. This brings us to the question:
How Do You Solve Data Science Problems?
A problem statement can be solved using the following steps:-
- Define the problem statement/business requirment
- Data Collection
- Data Cleaning
- Data preprocessing(feature engineering)
- Exploratory Data Analysis(EDA)
- Data Modelling
- Hyper parameter tunning
let's look at the each steps in detail:-
- step1:Defining the problem statement
- Before you even begin a Data Science project, you must define the problem you’re trying to solve. At this stage, you should be clear with the objectives of your project.
- step2:Data collection
- Like the name suggests at this stage you must acquire all the data needed to solve the problem. Collecting data is not very easy because most of the time you won’t find data sitting in a database, waiting for you. Instead, you’ll have to go out, do some research and collect the data or scrape it from the internet.
- step3:Data cleaning
- Here comes the main task in which a data scientist spends a good amount of time in data cleaning .So your ultimate accuracy of the model depends on how clean is your data.Data cleaning is the process of removing redundant, missing, duplicate and unnecessary data. This stage is considered to be one of the most time-consuming stages in Data Science. However, in order to prevent wrongful predictions, it is important to get rid of any inconsistencies in the data.
- step4:Data preprocessing
- This step involves various techniques of data preprocessing like feature scaling,normalization,standardization and etc
- step5:Exploratory data analysis
- Once you’re done cleaning the data, it is time to get the inner Sherlock Holmes out. At this stage in a Data Science life-cycle, you must detect patterns and trends in the data. This is where you retrieve useful insights and study the behavior of the data. At the end of this stage, you must start to form hypotheses about your data and the problem you are tackling.you will definetly enjoy doing this task.
- step6:Data modelling
- This stage is all about building a machine learning or a deep learning model .This stage always begins with a process called Data Splicing, where you split your entire data set into two proportions. One for training the model (training data set) and the other for testing the efficiency of the model (testing data set).
- step7:Data optimization
- This is the final stage in the data science project life cycle. In this stage you have to apply some hyper parameter tunning techniques to tune your model and improve the accuarcy of the model .In this process I will use some of the effective techniques to perform hyper parameter tunning like Grid search cv and Randomized search cv .In case of deep learning model like ANN I will change the weights of the neural links(to know more about neural networks refer by article on ANN deep learning )