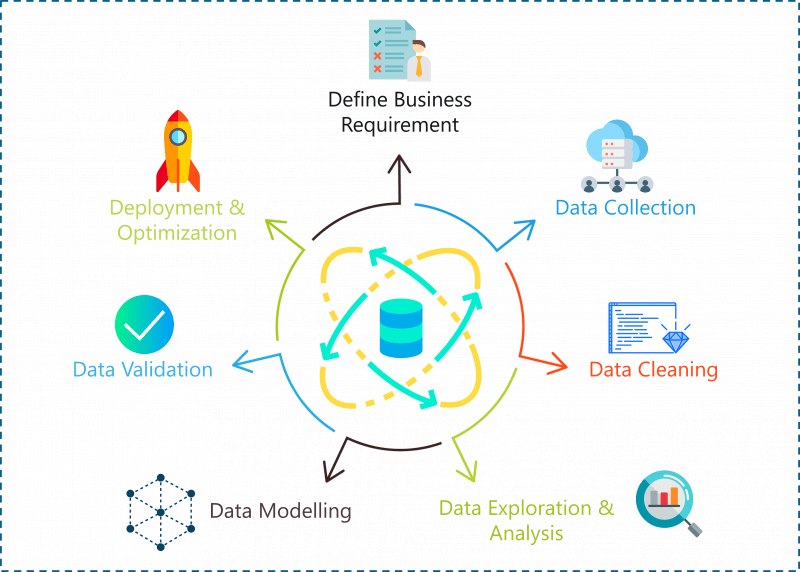
We all machine learning and data science aspirants must have participated in hackathons to test our skills in Machine Learning sometime or the other. Well, Some problem statement that we need to solve could be related to regression and some could be on classification. Let’s suppose, we are in one, and we have done all the hard work of pre-processing the data, worked hard on generating new features, applied them to our data to get the base model
So now,we are ready with our base model and want to test our algorithm on test data or outside data, and we feel that the accuracy we got is somewhat okayish!!.In that case we want to increase the accuracy of the model by method called hyper-parameter tunning
So now what are this parameters and hyperparameters?
Model parameters are the properties of the training data that are learnt during training by the classifier or other ML models.Model parameters differ for each experiment and depend on the type of data and task at hand.
Model hyperparameters are common for similar models and cannot be learnt during training but are set beforehand.
- Now let's see the hyper parameter tunning techniques involved in machine learning and deep learning:-
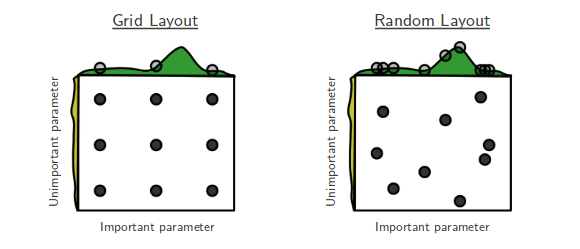
- -->Grid Search:- As the name indicates, Grid-searching is the process of scanning the data to configure optimal parameters for a given model in the grid. What this means is that the parameters search is done in the entire grid of the selected data.
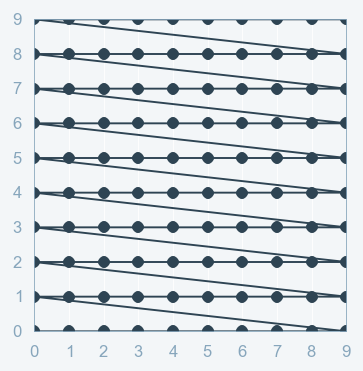
- This is very important as the whole model accuracy depends on the hyper parameter optimization
#Example of Grid Search
# Load the dataset
x, y = load_dataset()
# Create model for KerasClassifier
def create_model(hparams1=dvalue, hparams2=dvalue, ... hparamsn=dvalue):
...
model = KerasClassifier(build_fn=create_model)
# Define the range
hparams1 = [2, 4, ...]
hparams2 = ['elu', 'relu', ...]
...
hparamsn = [1, 2, 3, 4, ...]
# Prepare the Grid
param_grid = dict(hparams1=hparams1,
hparams2=hparams2,
...
hparamsn=hparamsn)
# GridSearch in action
grid = GridSearchCV(estimator=model,
param_grid=param_grid,
n_jobs=,
cv=,
verbose=)
grid_result = grid.fit(x, y)
# Show the results
print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_))
means = grid_result.cv_results_['mean_test_score']
stds = grid_result.cv_results_['std_test_score']
params = grid_result.cv_results_['params']
for mean, stdev, param in zip(means, stds, params):
print("%f (%f) with: %r" % (mean, stdev, param))
One point to remember while performing Grid Search is that the more parameters we have, the more time and space will be taken by the parameters to perform the search. This is where the Curse of Dimensionality comes to picture too. This means the more dimensions we add, the more the search will explode in time complexity
NOTE:-use grid search technique if you have less number of dimension otherwise it will take plenty of time for execution to finsh
- -->Randomized search:-Another type of Hyperparameter tuning is called Random Search. Random Search does its job of selecting the parameters randomly. It is similar to Grid Search, but it is known to yield better results than Grid Search.
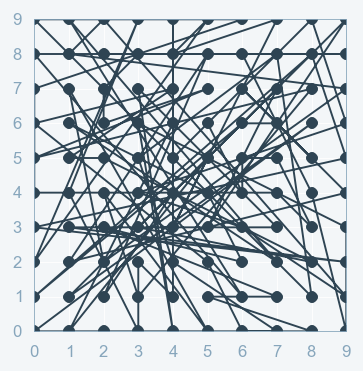
```
## Example of Random Search
# Load the dataset
X, Y = load_dataset()
# Create model for KerasClassifier
def create_model(hparams1=dvalue, hparams2=dvalue, ... hparamsn=dvalue):
...
model = KerasClassifier(build_fn=create_model)
# Specify parameters and distributions to sample from
hparams1 = randint(1, 100)
hparams2 = ['elu', 'relu', ...]
...
hparamsn = uniform(0, 1)
# Prepare the Dict for the Search
param_dist = dict(hparams1=hparams1,
hparams2=hparams2,
...
hparamsn=hparamsn)
# Search in action!
n_iter_search = 16 # Number of parameter settings that are sampled.
random_search = RandomizedSearchCV(estimator=model,
param_distributions=param_dist,
n_iter=n_iter_search,
n_jobs=,
cv=,
verbose=)
random_search.fit(X, Y)
# Show the results
print("Best: %f using %s" % (random_search.best_score_, random_search.best_params_))
means = random_search.cv_results_['mean_test_score']
stds = random_search.cv_results_['std_test_score']
params = random_search.cv_results_['params']
for mean, stdev, param in zip(means, stds, params):
print("%f (%f) with: %r" % (mean, stdev, param))
```
That's it with this article guys .Do give a like if you find it interesting and motivate me to write further
THANK YOU!!!